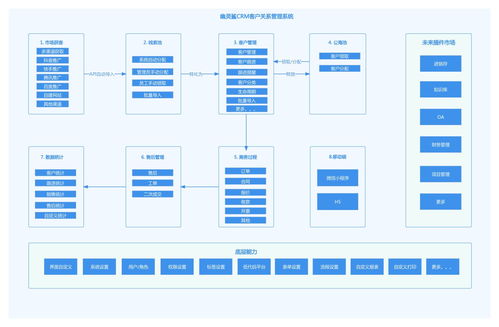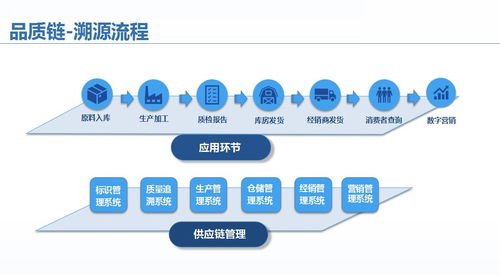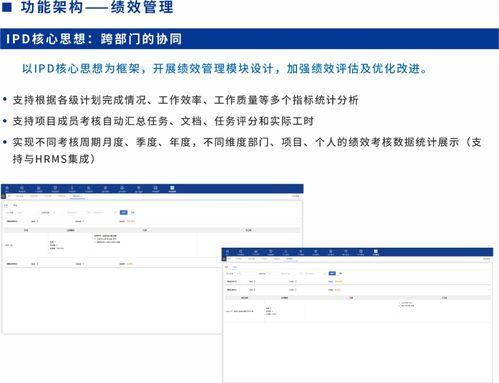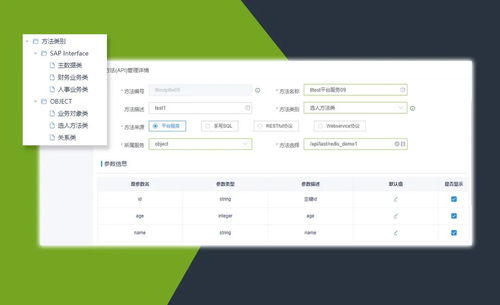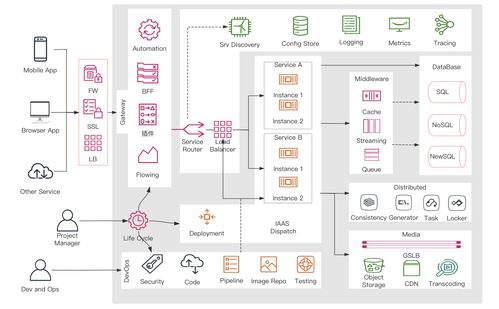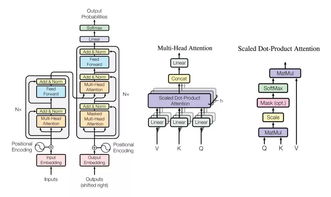
在2018年的WMT(Workshop on Machine Translation)机器翻译大赛中,阿里达摩院凭借其创新的大规模集成Transformer模型,一举夺魁,展现了在信息系统集成服务领域的卓越能力。这一成就不仅推动了机器翻译技术的进步,也为企业级信息系统解决方案提供了宝贵经验。在本次专访中,我们将深入探讨达摩院团队如何构建这一获奖系统,并分析其背后的技术策略与集成服务实践。
达摩院团队聚焦于Transformer模型的规模化集成。Transformer作为一种基于自注意力机制的神经网络架构,自提出以来便在自然语言处理任务中表现优异。单模型性能往往受限于数据多样性和模型复杂度。为此,团队采用了大规模集成方法,通过训练多个Transformer模型变体,并结合投票或加权平均机制进行结果融合。这种方法有效提升了翻译的准确性和鲁棒性,尤其在处理多语言、长句和领域特定文本时表现突出。例如,在WMT 2018的英德翻译任务中,集成的模型在BLEU分数上显著超越了单模型基准。
信息系统集成服务在这一过程中扮演了关键角色。阿里达摩院充分利用了其强大的云计算和分布式计算基础设施,实现了高效的数据处理、模型训练和推理部署。团队采用了模块化设计,将数据预处理、模型训练、评估和部署等环节无缝集成,确保了系统的可扩展性和可靠性。通过集成多源数据和服务,如多语言语料库和实时翻译API,系统能够适应多样化的用户需求,提供高质量的机器翻译服务。这种集成方法不仅优化了性能,还降低了运营成本,体现了信息系统集成服务在企业应用中的核心价值。
在技术实现上,达摩院团队强调了数据增强和超参数调优的重要性。他们通过引入噪声注入、回译等技术扩充训练数据,增强了模型的泛化能力。利用自动化工具进行超参数搜索,确保了每个集成模型的最优配置。团队还分享了在模型部署阶段的挑战,例如如何处理高并发请求和确保低延迟响应。通过集成容器化技术(如Docker)和负载均衡策略,系统在WMT评测中展现了出色的稳定性和效率。
值得一提的是,这一获奖系统不仅仅是技术创新的成果,还体现了阿里达摩院在产学研结合上的优势。团队与学术界合作,借鉴了最新的研究成果,并将其快速转化为实际应用。这种协同创新模式,加上强大的信息系统集成能力,使得达摩院能够在竞争激烈的WMT大赛中脱颖而出。
达摩院计划进一步扩展集成模型的应用范围,例如结合多模态数据和强化学习,以提升机器翻译在复杂场景下的表现。他们将持续优化信息系统集成服务,推动技术在更多行业落地,如电子商务、教育和医疗等领域。
阿里达摩院通过大规模集成Transformer模型和高效的信息系统集成服务,成功打造了WMT 2018机器翻译获胜系统。这一案例不仅展示了技术在突破语言障碍中的潜力,也为全球企业提供了可复用的集成解决方案。我们期待看到更多创新从达摩院诞生,推动人工智能与信息服务的深度融合。